Foreground Rendering
ChatSim adopts a novel multi-camera lighting estimation. With predicted environment lighting, we use Blender to render the scene-consistent foreground objects.
Scene simulation in autonomous driving has gained significant attention because of its huge potential for generating customized data. However, existing editable scene simulation approaches face limitations in terms of user interaction efficiency, multi-camera photo-realistic rendering and external digital assets integration. To address these challenges, this paper introduces ChatSim, the first system that enables editable photo-realistic 3D driving scene simulations via natural language commands with external digital assets. To enable editing with high command flexibility, ChatSim leverages a large language model (LLM) agent collaboration framework. To generate photo-realistic outcomes, ChatSim employs a novel multi-camera neural radiance field method. Furthermore, to unleash the potential of extensive high-quality digital assets, ChatSim employs a novel multi-camera lighting estimation method to achieve scene-consistent assets' rendering. Our experiments on Waymo Open Dataset demonstrate that ChatSim can handle complex language commands and generate corresponding photo-realistic scene videos.
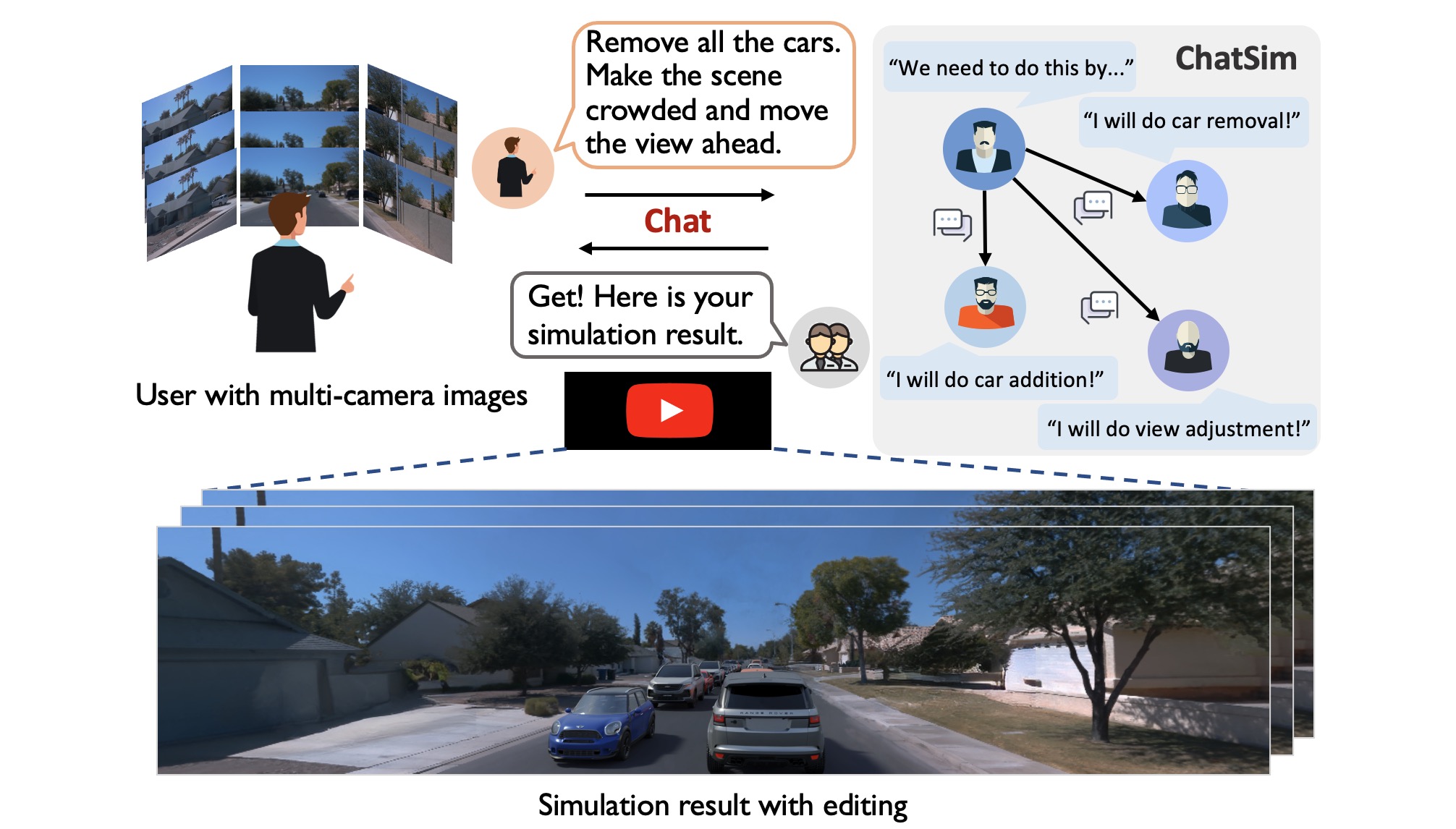
To address complex or abstract user commands effectively, ChatSim adopts a large language model (LLM)-based multi-agent collaboration framework. The key idea is to exploit multiple LLM agents, each with a specialized role, to decouple an overall simulation demand into specific editing tasks, thereby mirroring the task division and execution typically founded in the workflow of a human-operated company. This workflow offers two key advantages for scene simulation. First, LLM agents' ability to process human language commands allows for intuitive and dynamic editing of complex driving scenes, enabling precise adjustments and feedback. Second, the collaboration framework enhances simulation efficiency and accuracy by distributing specific editing tasks, ensuring improved task completion rates.
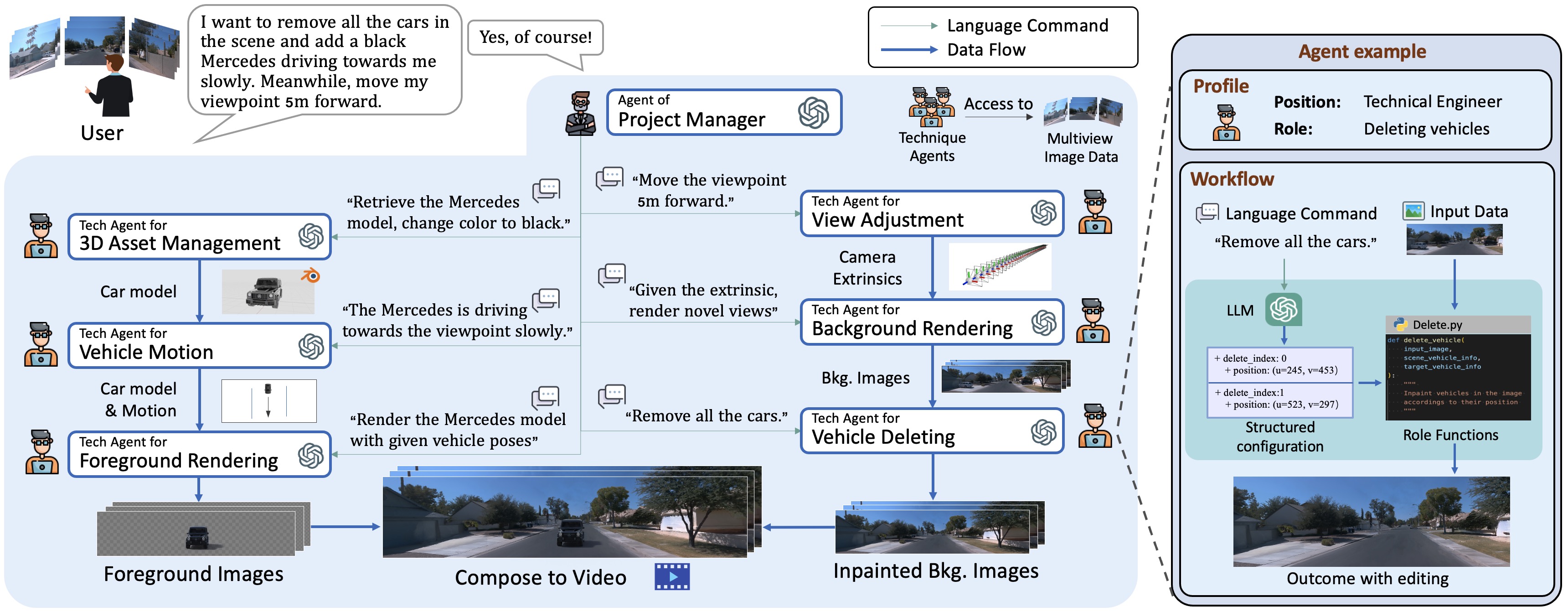
ChatSim adopts a novel multi-camera lighting estimation. With predicted environment lighting, we use Blender to render the scene-consistent foreground objects.
ChatSim introduces an innovative multi-camera radiance field approach to tackle the challenges of inaccurate poses and inconsistent exposures among surrounding cameras in autonomous vehicles. This method enables the rendering of ultra-wide-angle images that exhibit consistent brightness across the entire image.
@InProceedings{wei2024editable,
title={Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents},
author={Yuxi Wei and Zi Wang and Yifan Lu and Chenxin Xu and Changxing Liu and Hao Zhao and Siheng Chen and Yanfeng Wang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month={June},
year={2024},
}